Afin de répondre à différents besoins, la transposition de RDA pour les bibliothèques françaises, RDA-FR, se décline en deux modalités. Le code de catalogage RDA-FR est conçu et destiné aux catalogueurs tandis que l’ontologie RDA-FR est destinée aux développeurs.
Quel est l’objectif du code de catalogage RDA-FR ?
Les professionnels des bibliothèques et/ou de l’information s’appuient sur des instructions et des directives communes pour décrire leurs ressources documentaires. Celles-ci évoluent régulièrement pour répondre au mieux aux exigences des usagers. Conçu pour faciliter la recherche d’informations sur une ressource documentaire dans le contexte des technologies du web, le code de catalogage RDA-FR vise à ce que la description bibliographique et sa structuration répondent mieux aux différentes tâches des utilisateurs en ligne (trouver, identifier, choisir, obtenir, naviguer).
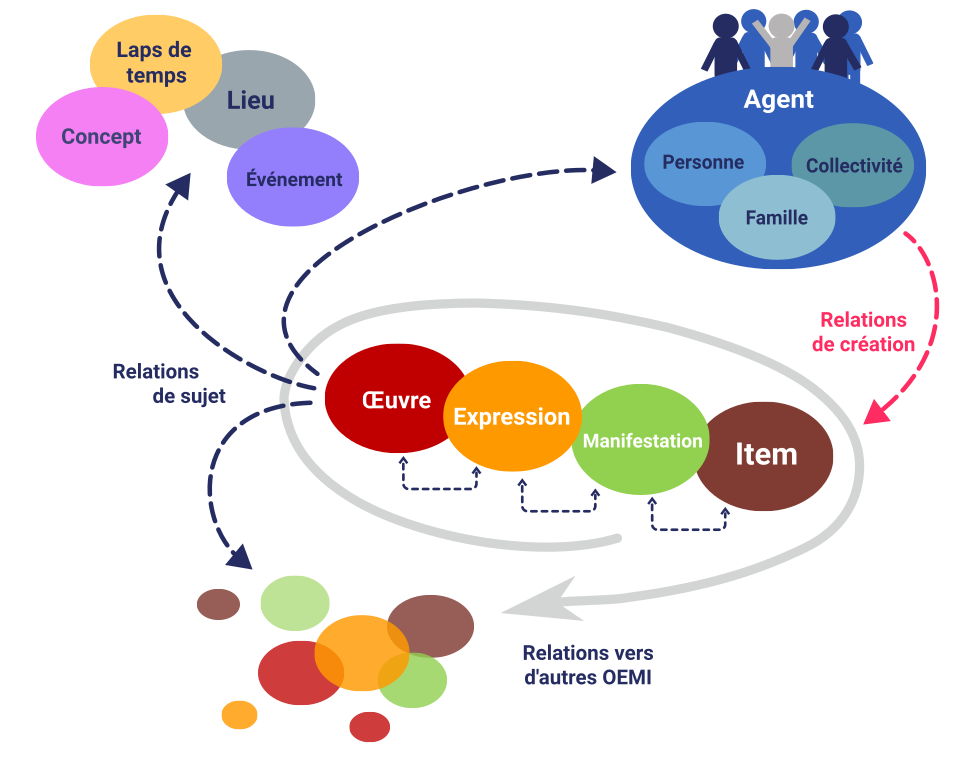
Le code de catalogage RDA-FR (déclinaison française de RDA) remplacera, à terme, les normes françaises de catalogage publiées par l’Afnor. Il donne des indications sur l’identification et la description des ressources documentaires en se fondant sur le modèle conceptuel IFLA LRM. Les entités RDA-FR, une déclinaison des entités IFLA LRM appliquées à un contexte de catalogage, permettent de définir qu’un document sera analysé au travers de la description de l’œuvre qu’il contient, l’expression qui réalise cette œuvre, la manifestation qui la matérialise et l’item qui l’exemplifie.
Le rôle du code de catalogage est de fixer les règles de description d’une ressource dans un catalogue et d’expliciter les liens qui relient ces entités aux agents impliqués (un auteur, un éditeur) ou aux concepts concernés (un thème, une période). Ce code est librement et gratuitement consultable sur le site https://code.rdafr.fr.
Quel est l’objectif de l’ontologie RDA-FR ?
Le code de catalogage RDA-FR est en train d’être relu, entité par entité, pour être exprimé sous forme d’ontologie RDF. Cette ontologie exprime chaque entité et ses attributs, ainsi que les différentes relations définies entre elles par le code de catalogage, selon le formalisme RDF utilisé dans l’univers du web de données (ou linked open data).
Cette ontologie permet aux agences bibliographiques et aux éditeurs de SGB (systèmes de gestion de bibliothèques) de concevoir et diffuser leurs métadonnées conformément au code de catalogage à travers les technologies du web de données, en favorisant l’interopérabilité avec les données du web.
La version HTML de l’ontologie est publiée sur le site https://rdafr.fr. La version SHACL (permettant d’appliquer des règles de conformité sur les données structurées avec cette ontologie) est accessible sur le GitHub du programme Transition bibliographique : https://github.com/transition-bibliographique/ontologie-rda-fr.
Date de la dernière modification: 2 février 2024